C# Skip List
Skip List
A Skip List in C# is a data structure that can search through items faster than a regular C# List. It works based on the idea of a LinkedList combined with probability.
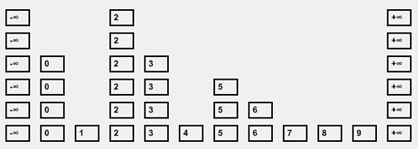
A Skip List has multiple LinkedLists stacked "on top of each other". Each LinkedList contains a copy of only some of the items in the total collection. Thus each value inserted into a Skip List has a tower of its value across multiple LinkedLists. The "height" of a value's tower is random.
Searching a Skip List is then done from top to bottom, which leads to very efficient search times.
Determine Tower Height
The most common way to determine to how many levels to add a value is with "coin tosses". A coin is tossed over and over until tails comes up. The total number of heads is the number of levels the value will have. In our C# Skip List the "coin toss" is done with the built-in pseudonumber Random generator.
Technically there is the probability that heads will keep coming up for a large number of times, leading to a giant value tower. The chances of this however are unlikely. For those who like to play it safe, a Skip List can be programmed to limit the maximum number of levels allowed. The lower the value the higher the chance that the Skip List will act like a single Linked List (which means slow searching times).
Skip List Levels
A single Skip List level consists of at minimum two nodes. One will be the header node (which can be represented as negative infinity) and a footer node (which can be represented as positive infinity). In our C# implementation of Skip List the header and footer nodes are their own class.
Insert to Skip List
Inserting to a Skip List involves two aspects. First is to determine the height of the value's tower, as explained above. Secondly the value must be inserted in order. To do so, our C# Skip List searches for the biggest element in the skip list that is LESS than the value being inserted. The value is then inserted as the next item.
Because a header and footer node are present in every level, the element will always be inserted between two existing nodes. That is, worst case it is inserted between negative and positive infinity.
The processes is repeated for every level required. Keep in mind that each level is simply storing a reference to the same value. So the space requirements for a Skip List are not as terrible as it may sound.
Remove Elements
Removing an element is fairly straight forward. The important thing to remember is that the element must be removed from ALL the levels. And since there is a header and footer node for each level, no level will be left without any nodes.
However an upper level (one that is not the bottom-most level) that has only a header node and a footer node can be considered empty. To keep our C# Skip List efficient, if removing an element leaves "empty" levels, they too must be removed.
Searching a C# Skip List
Searching a Skip List can be very fast. The search begins at the Top Left corner of a Skip List. The current node being compared changes depending on the value:
- If the current node (starting on the top left node) is smaller than the value being searched
- Move the cursor to the next node on the right, UNLESS that node is bigger than the target value
- If the next node is in fact bigger, then move the cursor down a level instead
Following that searching pattern, the cursor will eventually either reach the target value or move past the bottom-most level, at which point the value can be declared not to exist in the list.
Notice how LinkedLists at lower levels of the C# Skip List beginning searching from the position of the last Linked List. The behavior is possible because items are kept in sorted order.
Notes on Skip List
The C# Skip List keeps a reference to only two nodes: the top left node, and the bottom left node. The top left node is used for searchign while the bottom left node is used for scanning the elements in the collection one at a time (the bottom-most level is the only one guaranteed to have every element in the list).
Each node in the Skip List has a reference to four other nodes: the ones left and right, and the ones above and below. However only two references are needed when adding and searching: Right and Below. The other two are in case future programmers need them.
Finally insertion in a C# Skip List is relatively slow compared to List<>, but searching times as fast, even as fast as binary trees.